SQL for Event Driven Systems
This post will walk through for data aggregations on event based systems. Some software systems emit event messages to indicate a state change occurred. Events are easy to store in a data warehouse, but analyzing these events can be tricky in SQL. Check out my SQL Prequel post for a more basic tutorial.
Sample data
In this example we consider a “printer”. It reports its status one of three values:
- EXECUTE - processing work
- IDLE - ready for work
- FAULTED - unable to process work
Whenever the printer status changes, it emits a status changed event that contains the new status and optionally a reason for the change.
The sample data looks like this:
| printer_id | event_time | printer_status | reason_code |
|------------|---------------------|----------------|-------------|
| p2 | 2022-05-04 00:01:05 | EXECUTE | NEW_PRINT |
| p2 | 2022-05-04 00:02:55 | IDLE | FINISHED |Aggregate time in state
First we will remove duplicate statuses that appear in order.
WITH label_new_state AS(
SELECT *,
LAG(printer_status, 1, 'first') OVER (PARTITION BY printer_id ORDER BY event_time) != printer_status AS is_new_state
FROM events
ORDER BY event_time
)
SELECT printer_id, event_time, printer_status, reason_code
FROM label_new_state
WHERE is_new_state=1 AND printer_id='p2'Result interactive:
| printer_id | event_time | printer_status | reason_code |
|------------|---------------------|----------------|-------------|
| p2 | 2022-05-04 00:01:05 | EXECUTE | NEW_PRINT |
| p2 | 2022-05-04 00:02:55 | IDLE | FINISHED |
| p2 | 2022-05-04 00:03:33 | EXECUTE | NEW_PRINT |
| p2 | 2022-05-04 00:04:45 | IDLE | FINISHED |
| p2 | 2022-05-04 00:06:11 | EXECUTE | NEW_PRINT |
| p2 | 2022-05-04 00:07:23 | IDLE | FINISHED |Then compute the start and end time for each status.
WITH label_new_state AS(
SELECT *,
LAG(printer_status, 1, 'first') OVER (PARTITION BY printer_id ORDER BY event_time) != printer_status AS is_new_state
FROM events
ORDER BY event_time
)
SELECT printer_id, event_time, printer_status, reason_code,
LEAD (event_time, 1, NULL) OVER (PARTITION BY printer_id ORDER BY event_time) AS next_event_time
FROM label_new_state
WHERE is_new_state=1 AND printer_id='p2'Result interactive:
| printer_id | event_time | printer_status | reason_code | next_event_time |
|------------|---------------------|----------------|-------------|---------------------|
| p2 | 2022-05-04 00:01:05 | EXECUTE | NEW_PRINT | 2022-05-04 00:02:55 |
| p2 | 2022-05-04 00:02:55 | IDLE | FINISHED | 2022-05-04 00:03:33 |
| p2 | 2022-05-04 00:03:33 | EXECUTE | NEW_PRINT | 2022-05-04 00:04:45 |
| p2 | 2022-05-04 00:04:45 | IDLE | FINISHED | 2022-05-04 00:06:11 |
| p2 | 2022-05-04 00:06:11 | EXECUTE | NEW_PRINT | 2022-05-04 00:07:23 |
| p2 | 2022-05-04 00:07:23 | IDLE | FINISHED | |Then we compute the duration
WITH label_new_state AS(
SELECT *,
LAG(printer_status, 1, 'first') OVER (PARTITION BY printer_id ORDER BY event_time) != printer_status AS is_new_state
FROM events
ORDER BY event_time
), next_times AS(
SELECT printer_id, event_time, printer_status, reason_code,
LEAD (event_time, 1, NULL) OVER (PARTITION BY printer_id ORDER BY event_time) AS next_event_time
FROM label_new_state
WHERE is_new_state=1
)
SELECT *, ROUND((JULIANDAY(next_event_time) - JULIANDAY(event_time)) * 86400) AS duration_sec
FROM next_times
WHERE printer_id='p2'Result interactive:
| printer_id | event_time | printer_status | reason_code | next_event_time | duration_sec |
|------------|---------------------|----------------|-------------|---------------------|--------------|
| p2 | 2022-05-04 00:01:05 | EXECUTE | NEW_PRINT | 2022-05-04 00:02:55 | 110 |
| p2 | 2022-05-04 00:02:55 | IDLE | FINISHED | 2022-05-04 00:03:33 | 38 |
| p2 | 2022-05-04 00:03:33 | EXECUTE | NEW_PRINT | 2022-05-04 00:04:45 | 72 |
| p2 | 2022-05-04 00:04:45 | IDLE | FINISHED | 2022-05-04 00:06:11 | 86 |
| p2 | 2022-05-04 00:06:11 | EXECUTE | NEW_PRINT | 2022-05-04 00:07:23 | 72 |
| p2 | 2022-05-04 00:07:23 | IDLE | FINISHED | | |Now we can compute the time in state for each printer (removing in order duplicates of the same state isn’t important for this aggregation so I removed that step).
WITH next_times AS(
SELECT printer_id, event_time, printer_status, reason_code,
LEAD (event_time, 1, NULL) OVER (PARTITION BY printer_id ORDER BY event_time) AS next_event_time
FROM events
), duration AS(
SELECT *, ROUND((JULIANDAY(next_event_time) - JULIANDAY(event_time)) * 86400) AS duration_sec
FROM next_times
)
SELECT printer_id, printer_status, SUM(duration_sec)
FROM duration
GROUP BY printer_id, printer_statusResult interactive:
| printer_id | printer_status | SUM(duration_sec) |
|------------|----------------|-------------------|
| p1 | EXECUTE | 35 |
| p1 | FAULT | 168 |
| p1 | IDLE | 180 |
| p2 | EXECUTE | 254 |
| p2 | IDLE | 124 |Get total faulted time for each reason_code
This is pretty simple from the previous query. We just don’t group by the printer_id
WITH next_times AS(
SELECT printer_id, event_time, printer_status, reason_code,
LEAD (event_time, 1, NULL) OVER (PARTITION BY printer_id ORDER BY event_time) AS next_event_time
FROM events
), duration AS(
SELECT *, ROUND((JULIANDAY(next_event_time) - JULIANDAY(event_time)) * 86400) AS duration_sec
FROM next_times
)
SELECT printer_status, SUM(duration_sec)
FROM duration
GROUP BY printer_statusResult interactive:
| printer_status | SUM(duration_sec) |
|----------------|-------------------|
| EXECUTE | 289 |
| FAULT | 168 |
| IDLE | 304 |Mean Time Between Failure & Mean Time to Recovery
Mean Time Between Failure (MTBF) is defined as:
MTBF = total lifespan of all devices / number of failuresMean Time to Repair (MTTR) is defined as:
MTTR = total time spent fixing failure / number of repairsFrom our data we will assume all machines were online for the entire window we analyze (lifespan of devices). We will need to calculate the total number of failures (transitions into FAULT). We also need the total time spent fixing failure, which we will match with the (time in faulted state).
Total machine hours
SELECT MIN(event_time), MAX(event_time)
FROM eventsResult interactive:
| MIN(event_time) | MAX(event_time) |
|---------------------|---------------------|
| 2022-05-04 00:01:00 | 2022-05-04 00:07:23 |This means we monitored 2 machines for 383 seconds, 766 machine-seconds.
Total FAULT time
WITH next_times AS(
SELECT printer_id, event_time, printer_status, reason_code,
LEAD (event_time, 1, NULL) OVER (PARTITION BY printer_id ORDER BY event_time) AS next_event_time
FROM events
), duration AS(
SELECT *, ROUND((JULIANDAY(next_event_time) - JULIANDAY(event_time)) * 86400) AS duration_sec
FROM next_times
)
SELECT printer_status, SUM(duration_sec)
FROM duration
WHERE printer_status='FAULT'
GROUP BY printer_statusResult interactive:
| printer_status | SUM(duration_sec) |
|----------------|-------------------|
| FAULT | 168 |Number of faults
Remove duplicate transitions then count the number of faults:
WITH label_new_state AS(
SELECT *,
LAG(printer_status, 1, 'first') OVER (PARTITION BY printer_id ORDER BY event_time) != printer_status AS is_new_state
FROM events
ORDER BY event_time
)
SELECT printer_id, COUNT(printer_status)
FROM label_new_state
WHERE is_new_state=1 AND printer_status='FAULT'
GROUP BY printer_idResult interactive:
| printer_id | COUNT(printer_status) |
|------------|-----------------------|
| p1 | 3 |Compute the MTFB
MTFB = 766 seconds / 3 failures == 255 seconds/failureCompute the MTTR
MTTR = 168 seconds / 3 failures == 56 seconds/recoveryCustom transition logic
I have a theory that the data the printer reports is inaccurate. The printer often reports IDLE between two different faulted statuses. For example:
- a printer runs out of ink
- gets reset
- the top is opened to replace the place the ink
- a new print is started
The data follows:
| printer_id | event_time | printer_status | reason_code |
|------------|---------------------|----------------|------------------|
| p1 | 2022-05-04 00:01:00 | EXECUTE | NEW_PRINT |
| p1 | 2022-05-04 00:01:35 | FAULT | NO_INK |
| p1 | 2022-05-04 00:01:36 | IDLE | RESET |
| p1 | 2022-05-04 00:02:05 | FAULT | NO_INK |
| p1 | 2022-05-04 00:02:18 | IDLE | SHUTDOWN |
| p1 | 2022-05-04 00:04:11 | FAULT | ACCESS_DOOR_OPEN |
| p1 | 2022-05-04 00:05:11 | FAULT | ACCESS_DOOR_OPEN |
| p1 | 2022-05-04 00:06:11 | FAULT | ACCESS_DOOR_OPEN |
| p1 | 2022-05-04 00:06:45 | IDLE | RESET |
| p1 | 2022-05-04 00:07:23 | EXECUTE | NEW_PRINT |In this example I see two concerning things, mis-reported IDLE time and consecutive FAULTs.
We have idle time reported during the reset and during the time between the shutdown and when the technician opens the door. I wouldn’t consider this machine idle, because even if a fault sensor isn’t actively triggered, if an operator tried to start a print the print would fail. Based on systems like Overall Equipment Effectiveness (OEE), I reserve IDLE for times when the machine is capable of producing output but it is not producing; for example there are no new print jobs.
When we aggregate total time in fault for each reason code, during this occurrence most of the time would be counted towards door open. This might be useful, and we can encourage personnel to close the door more often but we might also want to add this time to the the NO_INK reason instead so we better understand how much total available time is impacted to to out of ink issues.
To do this we will do a custom aggregation that will enforce a new rule. Once the machine enters FAULT state other IDLE and FAULT statuses are ignored. All the time between a fault and the next EXECUTE state is attributed to the first FAULT in a chain.
Remove repeated statuses
When the printer’s status does not change for more than one minute, the printer replays its status. This means we have repeated events for the same status. These can be removed like above, I also added a row number:
WITH label_new_state AS(
SELECT *,
LAG(printer_status, 1, 'first') OVER (PARTITION BY printer_id ORDER BY event_time) != printer_status AS is_new_state
FROM events
ORDER BY event_time
), setup_rn AS(
SELECT printer_id, event_time, printer_status,
LEAD (event_time, 1, NULL) OVER (PARTITION BY printer_id ORDER BY event_time) AS next_event_time,
ROW_NUMBER() OVER (PARTITION BY printer_id ORDER BY event_time) AS rn
FROM label_new_state
WHERE is_new_state=1
)
SELECT *
FROM setup_rnResult interactive:
| printer_id | event_time | printer_status | next_event_time | rn |
|------------|---------------------|----------------|---------------------|----|
| p1 | 2022-05-04 00:01:00 | EXECUTE | 2022-05-04 00:01:35 | 1 |
| p1 | 2022-05-04 00:01:35 | FAULT | 2022-05-04 00:01:36 | 2 |
| p1 | 2022-05-04 00:01:36 | IDLE | 2022-05-04 00:02:05 | 3 |
| p1 | 2022-05-04 00:02:05 | FAULT | 2022-05-04 00:02:18 | 4 |
| p1 | 2022-05-04 00:02:18 | IDLE | 2022-05-04 00:04:11 | 5 |
| p1 | 2022-05-04 00:04:11 | FAULT | 2022-05-04 00:06:45 | 6 |
| p1 | 2022-05-04 00:06:45 | IDLE | 2022-05-04 00:07:23 | 7 |
| p1 | 2022-05-04 00:07:23 | EXECUTE | | 8 |
| p2 | 2022-05-04 00:01:05 | EXECUTE | 2022-05-04 00:02:55 | 1 |
| p2 | 2022-05-04 00:02:55 | IDLE | 2022-05-04 00:03:33 | 2 |
| p2 | 2022-05-04 00:03:33 | EXECUTE | 2022-05-04 00:04:45 | 3 |
| p2 | 2022-05-04 00:04:45 | IDLE | 2022-05-04 00:06:11 | 4 |
| p2 | 2022-05-04 00:06:11 | EXECUTE | 2022-05-04 00:07:23 | 5 |
| p2 | 2022-05-04 00:07:23 | IDLE | | 6 |Time for the recursive bit, we will step through the row numbers one at a time starting at each FAULT and labeling each row after a FAULT with an indicator that it should be skipped until we reach an EXECUTE. Recursion allows us to implement iterative logic into SQL. Recursive queries have two main parts, a initial query and a recursive part. The output of the initial query is fed into the recursive part until nothing is returned
For example we can use recursive SQL to count out odd numbers:
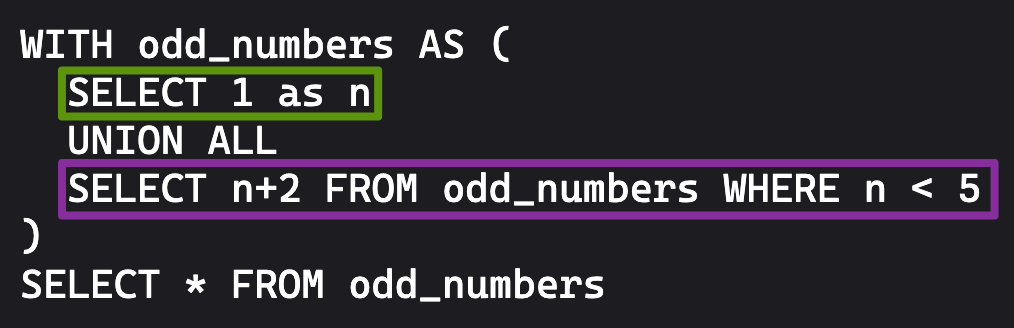
The query steps look like this where UNION ALL combines the results to list the odd numbers 1-5:
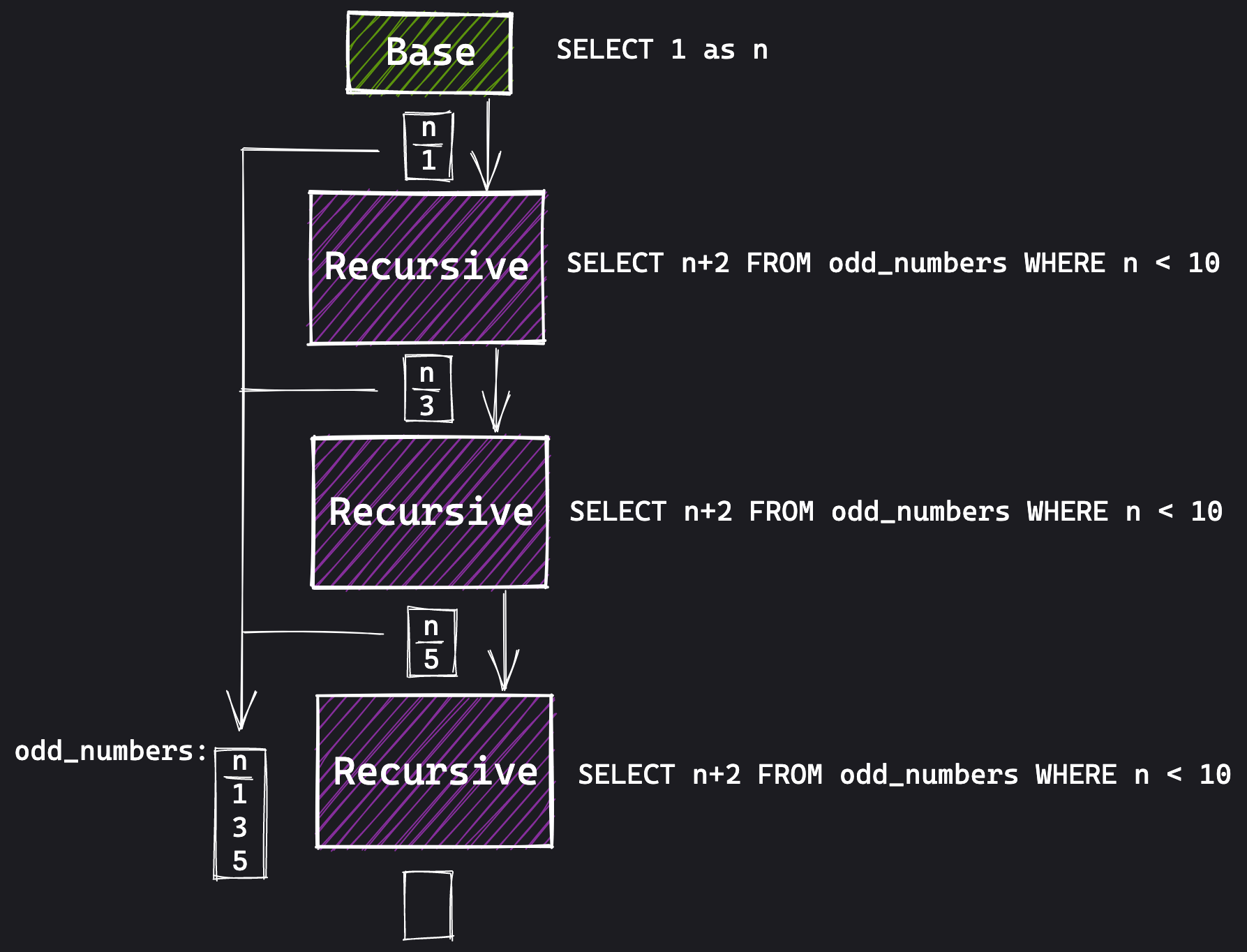
We do the same with our logic but instead the base case is when the device is in a FAULT state, and from there we look forward to list all intermediate row numbers until the device returns to EXCUTE. These rows can then be filtered out of our data.
WITH label_new_state AS(
SELECT *,
LAG(printer_status, 1, 'first') OVER (PARTITION BY printer_id ORDER BY event_time) != printer_status AS is_new_state
FROM events
ORDER BY event_time
), setup_rn AS(
SELECT printer_id, event_time, printer_status,
LEAD (event_time, 1, NULL) OVER (PARTITION BY printer_id ORDER BY event_time) AS next_event_time,
ROW_NUMBER() OVER (PARTITION BY printer_id ORDER BY event_time) AS rn
FROM label_new_state
WHERE is_new_state=1
), skip_extra_all AS(
SELECT rn,
printer_id,
printer_status,
0 AS keep -- 0 for intermediate FAULTS but we will keep the first one later
FROM setup_rn
WHERE printer_status = 'FAULT' --starting data
UNION ALL
SELECT
setup_rn.rn,
setup_rn.printer_id,
setup_rn.printer_status,
0 AS keep
FROM skip_extra_all, setup_rn
WHERE setup_rn.rn = skip_extra_all.rn + 1 AND setup_rn.printer_id = skip_extra_all.printer_id AND setup_rn.printer_status != 'EXECUTE'
)
SELECT *
FROM skip_extra_allResult interactive:
| rn | printer_id | printer_status | keep |
|----|------------|----------------|------|
| 2 | p1 | FAULT | 0 |
| 4 | p1 | FAULT | 0 |
| 6 | p1 | FAULT | 0 |
| 3 | p1 | IDLE | 0 |
| 5 | p1 | IDLE | 0 |
| 7 | p1 | IDLE | 0 |
| 4 | p1 | FAULT | 0 |
| 6 | p1 | FAULT | 0 |
| 5 | p1 | IDLE | 0 |
| 7 | p1 | IDLE | 0 |
| 6 | p1 | FAULT | 0 |
| 7 | p1 | IDLE | 0 |The recursive query returns some rows more than once so we filter those out.
WITH label_new_state AS(
SELECT *,
LAG(printer_status, 1, 'first') OVER (PARTITION BY printer_id ORDER BY event_time) != printer_status AS is_new_state
FROM events
ORDER BY event_time
), setup_rn AS(
SELECT printer_id, event_time, printer_status,
LEAD (event_time, 1, NULL) OVER (PARTITION BY printer_id ORDER BY event_time) AS next_event_time,
ROW_NUMBER() OVER (PARTITION BY printer_id ORDER BY event_time) AS rn
FROM label_new_state
WHERE is_new_state=1
), skip_extra_all AS(
SELECT rn,
printer_id,
printer_status,
0 AS keep -- 0 for intermediate FAULTS but we will keep the first one later
FROM setup_rn
WHERE printer_status = 'FAULT' --starting data
UNION ALL
SELECT
setup_rn.rn,
setup_rn.printer_id,
setup_rn.printer_status,
0 AS keep
FROM skip_extra_all, setup_rn
WHERE setup_rn.rn = skip_extra_all.rn + 1 AND setup_rn.printer_id = skip_extra_all.printer_id AND setup_rn.printer_status != 'EXECUTE'
), skip_extra AS(
SELECT rn, printer_id, keep FROM skip_extra_all GROUP BY rn, printer_id
)
SELECT * FROM skip_extraResult interactive:
| rn | printer_id | keep |
|----|------------|------|
| 2 | p1 | 0 |
| 3 | p1 | 0 |
| 4 | p1 | 0 |
| 5 | p1 | 0 |
| 6 | p1 | 0 |
| 7 | p1 | 0 |We join this back onto our prepared data and use IS_NULL to decide which rows to drop and a LAG function to keep the first FAULT.
WITH label_new_state AS(
SELECT *,
LAG(printer_status, 1, 'first') OVER (PARTITION BY printer_id ORDER BY event_time) != printer_status AS is_new_state
FROM events
ORDER BY event_time
), setup_rn AS(
SELECT printer_id, event_time, printer_status,
LEAD (event_time, 1, NULL) OVER (PARTITION BY printer_id ORDER BY event_time) AS next_event_time,
ROW_NUMBER() OVER (PARTITION BY printer_id ORDER BY event_time) AS rn
FROM label_new_state
WHERE is_new_state=1
), skip_extra_all AS(
SELECT rn,
printer_id,
printer_status,
0 AS keep -- 0 for intermediate FAULTS but we will keep the first one later
FROM setup_rn
WHERE printer_status = 'FAULT' --starting data
UNION ALL
SELECT
setup_rn.rn,
setup_rn.printer_id,
setup_rn.printer_status,
0 AS keep
FROM skip_extra_all, setup_rn
WHERE setup_rn.rn = skip_extra_all.rn + 1 AND setup_rn.printer_id = skip_extra_all.printer_id AND setup_rn.printer_status != 'EXECUTE'
), skip_extra AS(
SELECT rn, printer_id, keep FROM skip_extra_all GROUP BY rn, printer_id
), should_skip_t AS(
SELECT *
, IFNULL(keep, 1) AS keep2
, IFNULL(LAG(keep, 1, 1) OVER (PARTITION BY setup_rn.printer_id ORDER BY event_time), 1) = 0 AND printer_status != 'EXECUTE' AS should_skip
FROM setup_rn LEFT JOIN skip_extra ON setup_rn.rn = skip_extra.rn AND setup_rn.printer_id = skip_extra.printer_id
)
SELECT * FROM should_skip_t
ORDER BY printer_id, event_timeResult interactive:
| printer_id | event_time | printer_status | next_event_time | rn | rn:1 | printer_id:1 | keep | keep2 | should_skip |
|------------|---------------------|----------------|---------------------|----|------|--------------|------|-------|-------------|
| p1 | 2022-05-04 00:01:00 | EXECUTE | 2022-05-04 00:01:35 | 1 | | | | 1 | 0 |
| p1 | 2022-05-04 00:01:35 | FAULT | 2022-05-04 00:01:36 | 2 | 2 | p1 | 0 | 0 | 0 |
| p1 | 2022-05-04 00:01:36 | IDLE | 2022-05-04 00:02:05 | 3 | 3 | p1 | 0 | 0 | 1 |
| p1 | 2022-05-04 00:02:05 | FAULT | 2022-05-04 00:02:18 | 4 | 4 | p1 | 0 | 0 | 1 |
| p1 | 2022-05-04 00:02:18 | IDLE | 2022-05-04 00:04:11 | 5 | 5 | p1 | 0 | 0 | 1 |
| p1 | 2022-05-04 00:04:11 | FAULT | 2022-05-04 00:06:45 | 6 | 6 | p1 | 0 | 0 | 1 |
| p1 | 2022-05-04 00:06:45 | IDLE | 2022-05-04 00:07:23 | 7 | 7 | p1 | 0 | 0 | 1 |
| p1 | 2022-05-04 00:07:23 | EXECUTE | | 8 | | | | 1 | 0 |
| p2 | 2022-05-04 00:01:05 | EXECUTE | 2022-05-04 00:02:55 | 1 | | | | 1 | 0 |
| p2 | 2022-05-04 00:02:55 | IDLE | 2022-05-04 00:03:33 | 2 | | | | 1 | 0 |
| p2 | 2022-05-04 00:03:33 | EXECUTE | 2022-05-04 00:04:45 | 3 | | | | 1 | 0 |
| p2 | 2022-05-04 00:04:45 | IDLE | 2022-05-04 00:06:11 | 4 | | | | 1 | 0 |
| p2 | 2022-05-04 00:06:11 | EXECUTE | 2022-05-04 00:07:23 | 5 | | | | 1 | 0 |
| p2 | 2022-05-04 00:07:23 | IDLE | | 6 | | | | 1 | 0 |After this a simple WHERE will restrict the result to our new data. We can recreate the above aggregations based on the newly filtered results. The whole query follows:
WITH label_new_state AS(
SELECT *,
LAG(printer_status, 1, 'first') OVER (PARTITION BY printer_id ORDER BY event_time) != printer_status AS is_new_state
FROM events
ORDER BY event_time
), setup_rn AS(
SELECT printer_id, event_time, printer_status, reason_code,
LEAD (event_time, 1, NULL) OVER (PARTITION BY printer_id ORDER BY event_time) AS next_event_time,
ROW_NUMBER() OVER (PARTITION BY printer_id ORDER BY event_time) AS rn
FROM label_new_state
WHERE is_new_state=1
), skip_extra_all AS(
SELECT rn,
printer_id,
printer_status,
0 AS keep -- 0 for intermediate FAULTS but we will keep the first one later
FROM setup_rn
WHERE printer_status = 'FAULT' --starting data
UNION ALL
SELECT
setup_rn.rn,
setup_rn.printer_id,
setup_rn.printer_status,
0 AS keep
FROM skip_extra_all, setup_rn
WHERE setup_rn.rn = skip_extra_all.rn + 1 AND setup_rn.printer_id = skip_extra_all.printer_id AND setup_rn.printer_status != 'EXECUTE'
), skip_extra AS(
SELECT rn, printer_id, keep FROM skip_extra_all GROUP BY rn, printer_id
), should_skip_t AS(
SELECT *
, IFNULL(keep, 1) AS keep2
, IFNULL(LAG(keep, 1, 1) OVER (PARTITION BY setup_rn.printer_id ORDER BY event_time), 1) = 0 AND printer_status != 'EXECUTE' AS should_skip
FROM setup_rn LEFT JOIN skip_extra ON setup_rn.rn = skip_extra.rn AND setup_rn.printer_id = skip_extra.printer_id
), filtered_data AS(
SELECT printer_id,
event_time,
printer_status,
reason_code
FROM should_skip_t
WHERE should_skip=0
ORDER BY printer_id, event_time
)
SELECT * FROM filtered_dataResult interactive:
| printer_id | event_time | printer_status | reason_code |
|------------|---------------------|----------------|-------------|
| p1 | 2022-05-04 00:01:00 | EXECUTE | NEW_PRINT |
| p1 | 2022-05-04 00:01:35 | FAULT | NO_INK |
| p1 | 2022-05-04 00:07:23 | EXECUTE | NEW_PRINT |
| p2 | 2022-05-04 00:01:05 | EXECUTE | NEW_PRINT |
| p2 | 2022-05-04 00:02:55 | IDLE | FINISHED |
| p2 | 2022-05-04 00:03:33 | EXECUTE | NEW_PRINT |
| p2 | 2022-05-04 00:04:45 | IDLE | FINISHED |
| p2 | 2022-05-04 00:06:11 | EXECUTE | NEW_PRINT |
| p2 | 2022-05-04 00:07:23 | IDLE | FINISHED |Updated MTBF / MTTR
Under the new data we still have a total of 766 machine seconds. This time there was 1 fault that took 348 seconds to recover:
MTBF = 766 seconds/failure
MTTR = 348 seconds/recoveryConclusion
This post showed how to use SQL widow functions and recursive SQL to analyze data stored from an event based system. Window function are effective on simple aggregations, and recursive queries can run short sequential logic to help with custom aggregations.